Datenabstrakte Schemata
Schemas sind eine der leistungsstärksten Funktionen in Data Abstract und ein großer Teil dessen, was es von anderen mehrschichtigen Frameworks unterscheidet.
Einfach ausgedrückt ist ein Schema eine Datei, die den Satz von Datentabellen definiert, mit denen eine mehrschichtige Anwendung arbeitet. Es definiert ihre Struktur und Beziehungen und wie sie sich auf die tatsächlichen Daten beziehen, die in der/den Backend-Datenbank(en) gespeichert sind.
Was wie ein einfaches Konzept klingt, eröffnet Data Abstract viele leistungsstarke Funktionen. Gehen wir also einen Schritt zurück und betrachten Sie Schemata genauer.
Traditioneller Datenzugriff der mittleren Ebene
Eine der Kernfunktionen jedes mehrschichtigen Datenbankprojekts besteht darin, auf Daten von Back-End-Datenbanksystemen zuzugreifen, diese Daten für Clients bereitzustellen und von Clients vorgenommene Änderungen wieder auf die Datenbank anzuwenden.
In den meisten mehrschichtigen Frameworks, einschließlich ADO.NET oder Delphis DataSnap, wird der Datenzugriff direkt von der mittleren Schicht abgewickelt, normalerweise indem Komponenten für einzelne Datensätze gelöscht, mit den richtigen SQL-Anweisungen konfiguriert usw Mittelschicht wird normalerweise direkt mit diesen Komponenten kommunizieren.
Dies koppelt die mittlere Schicht (und damit die gesamte Lösung) sehr eng an die zugrunde liegende Datenbank. Änderungen der Datenbankstruktur erfordern manuelle Änderungen der Komponenten und der konfigurierten SQL-Anweisungen; Ein kompletter Wechsel von Datenbanksystemen ist oft nicht möglich, ohne die mittlere Schicht von Grund auf neu zu erstellen.
Schemata
In Data Abstract trennen Schemas den Code der mittleren und Client-Ebene klar vom eigentlichen Datenzugriff. Das Schema definiert den Satz von Tabellen, auf die die Anwendung zugreift, und sowohl der Client als auch die mittlere Ebene codieren anhand der im Schema definierten Datenstruktur – unabhängig von einem bestimmten Datenbankformat.

Neben der Definition von Datentabellen und deren Feldern verwaltet das Schema auch die Zuordnung dieser Datentabellen zu den tatsächlichen physischen Tabellen in der Back-End-Datenbank. Dies kann (und wird in vielen Fällen) eine 1:1-Zuordnung sein, wobei im Schema definierte Tabellen direkt Tabellen in der Datenbank entsprechen, muss es aber nicht.
Das Schema enthält auch alle Informationen, die Data Abstract benötigt, um Daten abzurufen oder Aktualisierungen durchzuführen, sodass dieser gesamte Prozess von der Data Abstract-Bibliothek unter der Haube abgewickelt werden kann, ohne dass Benutzercode erforderlich ist.
Vorteile von Schemata
Zu den Vorteilen der oben beschriebenen Schemaarchitektur gehören die folgenden:
- Abstraktion des Benutzercodes (auf Client und mittlerer Ebene) vom tatsächlichen Datenzugriff.
- Der gesamte Benutzercode ist datenbankunabhängig.
- Datenzugriff und Updates können vollständig von der Bibliothek abgewickelt werden.
- Es muss kein SQL-Code geschrieben und gewartet werden (es sei denn, Sie möchten).
- Die Anwendung kann geändert werden, um verschiedene Back-End-Datenbanktypen ohne Codeänderungen zu verwenden.
- Die Anwendung kann an Datenbankänderungen angepasst werden, indem nur das Schema angepasst wird.
- Einfacher Zugriff auf verschiedene Datenbanksysteme aus derselben Codebasis.
- RAD Schema Modeler™-Anwendung zum Entwerfen und Verwalten von Schemata.
Lassen Sie uns einige dieser Punkte genauer untersuchen:
Abstraktion des Benutzercodes vom Datenzugriff
Wie bereits oben beschrieben, wird in einer typischen Data Abstract-Anwendung der gesamte Code so geschrieben, dass er mit den im Schema definierten Datentabellen kommuniziert. Der Code muss nicht wissen, welches Datenbanksystem im Back-End verwendet wird, wie SQL-Code generiert wird, um mit dieser Datenbank zu kommunizieren, oder welche Datenzugriffskomponenten benötigt werden.
Vergleichen Sie dies mit ADO.NET, wo Komponenten gelöscht werden müssen, die spezifisch für – sagen wir – SQL Server sind und SQL-Strings (ob handgeschrieben oder assistentengeneriert) enthalten. Wenn Sie später ein Oracle-Back-End anstelle von (oder zusätzlich zu) SQL Server verwenden möchten, kann keines davon wiederverwendet werden. Ähnliche Konzepte gelten für DataSnap oder andere Lösungen von Drittanbietern auf Delphi-Seite.
Im Gegensatz dazu muss sich Data Abstract-Middle-Tier-Code nicht darum kümmern (und wird in den meisten Fällen nicht einmal wissen), mit welcher Art von Datenbank er kommuniziert und welche Datenzugriffskomponenten oder -anbieter auf niedriger Ebene sein könnten an der eigentlichen Kommunikation mit der Datenbank beteiligt. Wenn überhaupt Benutzercode beteiligt ist (und dies in vielen Fällen nicht erforderlich ist), verwendet er Klassen, die von der Data Abstract-Bibliothek bereitgestellt werden, die diesen abstrahieren.
Der gesamte Benutzercode ist datenbankunabhängig
Da eine mittlere Ebene von Data Abstract diese Dinge nicht kennt oder sich darum kümmert, kann dieselbe Anwendung auf einer Vielzahl von Datenbanksystemen ausgeführt werden, wobei nur minimale (wenn überhaupt) Anpassungen im Schema vorgenommen werden müssen. In vielen Fällen reicht es aus, einfach eine neue Verbindungszeichenfolge zu definieren, um auf einen anderen Datenbanktyp abzuzielen.
Der Datenzugriff wird von der Bibliothek verwaltet, es muss kein SQL-Code geschrieben werden
Die Data Abstract-Bibliothek verarbeitet den gesamten Abruf und die Aktualisierung von Daten. Weil die schema enthält alle Informationen, die die Datentabellen auf die zugrunde liegende Datenbank abbilden, Data Abstract kann die erforderlichen SELECT-, INSERT-, UPDATE- und DELETE-SQL-Anweisungen im laufenden Betrieb generieren, wenn es Daten holen oder aktualisieren muss.
Die Bibliothek (bzw. die einzelnen Datenbanktreiber) kennen unterschiedliche SQL-Dialekte und können bei Bedarf je nach Datenbanktyp unterschiedliche SQL generieren. Es kann auch Feld- oder Tabellennamen berücksichtigen, die sich zwischen Back-End und Schema unterscheiden können.
Dies bedeutet natürlich nicht, dass sich eine Data Abstract-Mittelschicht muss auf automatisch generierten SQL-Code verlassen müssen. Schemas können benutzerdefiniertes oder fein abgestimmtes SQL für den Datenabruf und die Aktualisierung enthalten und bieten flexible Optionen, um bei Bedarf unterschiedlichen benutzerdefinierten SQL-Code für verschiedene Datenbanken bereitzustellen.
Anwendungen können geändert werden, um verschiedene Back-End-Datenbanktypen zu verwenden
Aus den gleichen Gründen macht es Data Abstract sehr einfach, Datenbanktypen im Handumdrehen zu wechseln. Da keiner der geschriebenen Codes an einen bestimmten Datenbanktyp gebunden ist oder diesen kennt, sondern die abstrahierten Datentabellen aus dem Schema verwendet, kann ein Wechsel des Datenbankanbieters so einfach sein wie das Definieren einer neuen Verbindungszeichenfolge oder – in komplexeren Szenarien – einige zusätzliche Schritte Anpassungen im Schema, um Unterschiede in den Datenbanken zu berücksichtigen.
Es muss kein Benutzercode geändert werden, es sei denn, er enthält ausdrücklich und absichtlich datenbankherstellerspezifischen Code.
Anwendungen können an Datenbankänderungen angepasst werden
Da Schemata eine Abstraktionsschicht über der Struktur der physischen Datenbank bereitstellen, können Anwendungen leicht an Datenbankänderungen angepasst werden, indem lediglich Zuordnungen im Schema angepasst werden. Beispielsweise können einfache Änderungen wie das Umbenennen eines Felds oder einer Tabelle im Schema vorgenommen werden – der Anwendungscode muss sich nie ändern, um die neuen Namen zu verwenden. Die Anwendung wird so funktionieren, wie sie ist.
Dies kann nicht nur Arbeit für die Aktualisierung des Anwendungscodes sparen, sondern kann auch die Notwendigkeit ersparen, allen Benutzern für diese Änderungen neue Clientanwendungen bereitzustellen.
Zugriff auf verschiedene Datenbanksysteme aus derselben Codebasis
Noch mächtiger als die Idee, leicht zwischen Datenbanktypen (oder -strukturen) umzuschalten, ist das Konzept, dieselbe Codebasis zu verwenden, um gleichzeitig mit verschiedenen Datenbanken zu kommunizieren. Da Schemas gleichzeitig explizit unterschiedliche Verbindungen und Mappings unterstützen können, kann ein Schema so entworfen werden, dass dieselbe Anwendung für verschiedene Datenbanken bereitgestellt werden kann, ohne dass eine erneute Kompilierung erforderlich ist. Ein Kunde führt Ihren Server der mittleren Ebene möglicherweise gegen Oracle aus, während ein anderer DB2 oder Microsoft SQL Server verwendet.
Es ist auch möglich, mehr als eine Back-End-Datenbank in einer einzelnen laufenden Serverinstanz zu unterstützen – ein Client kann an Daten aus einer Datenbank arbeiten, während ein anderer auf eine zweite Datenbank mit einem anderen Typ oder einer anderen Struktur zugreift.
Dies macht auch die Migration von Legacy-Datenbanken sehr einfach; Ein Server der mittleren Ebene kann so geschrieben sein, dass er mit einer alten CRM-Datenbank kommuniziert, die sich in Produktion befindet, während der Datenbankadministrator Daten in eine neue, besser strukturierte Datenbank migriert. Endbenutzer können sowohl auf die alte als auch auf die neue Datenbank zugreifen, bis die Migration abgeschlossen ist.
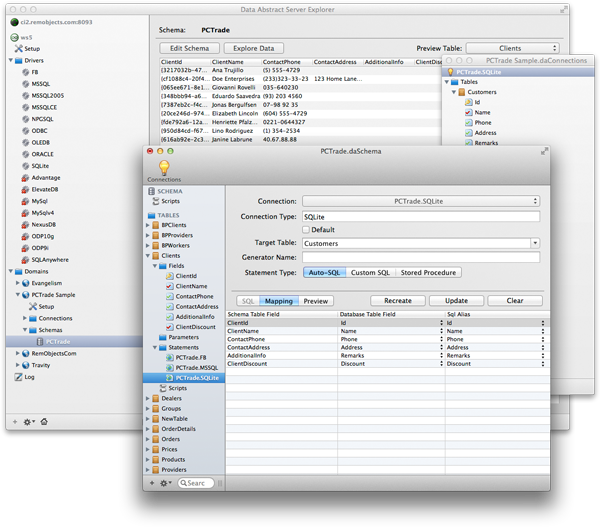
Schema Modeler zum Entwerfen von Schemas
Da Schemata eine so wichtige Säule der Data Abstract-Architektur sind, wird die Anwendung Schema Modeler bereitgestellt, die es Entwicklern oder Datenbankarchitekten ermöglicht, Schemata auf intuitive RAD-Weise zu definieren und zu entwerfen.
Schema Modeler integriert sich tief in die unterstützten IDEs, kann aber auch von Nicht-Entwicklern eigenständig verwendet werden. Es ist für Windows und Mac verfügbar. Weitere Details zum Schema Modeler finden Sie in der Dokumentation, hier.
Vielen Dank!
Ihre Nachricht wurde gesendet und jemand wird sich in Kürze, normalerweise innerhalb eines Werktages, bei Ihnen melden.
Bei technischen Fragen oder Support-Fragen besuchen Sie bitte auch unser RemObjects Talk Support-Forum sowie andere Support-Optionen .
Diese Website wird verwaltet von elitedevelopments als offizieller Premium Reselleer für Deuschland.
Alle Inhalte dieser Website sind Copyright RemObjects Software 2002-2026. Legal.
Elements™ Data Abstract™, Relativity™, Oxygene™, Hydrogene™ und andere namen und logos sind Eigentum von RemObjects Software, LLC. Mehr.
This Website is operated independently by elitedevelopments, as an official Premium Reseller for Germany.
All content is copyright RemObjects Software 2002-2026. All rights reserved. Legal.
